|
Esta sección viene a intentar introducir un poco al lector que no conoce SQL, en su mundo y a entender mejor los ejemplos que se han propuesto. No se intenta hacer un manual de SQL, sino simplemente recordar algunas de las características y comandos de este lenguaje. Como JDBC requiere que los drivers sean compatibles con la versión estándar ANSI SQL-92, esa será la que se comente, aunque en la actualidad SQL sigue evolucionando y mejorando, pasando de ser un sublenguaje de manejo de datos a un verdadero lenguaje de programación, pero hay que tener siempre presente que una de las primeras frases que aparece en la especificación oficial de JDBC es:
"In order to pass JDBC compliance tests and to be called ‘JDBC compliant’, we require that a driver support at least ANSI SQL-92 Entry Level"
Lo cual es claramente imposible de cumplir con drivers para sistemas de manejo de bases de datos antiguos (DBMs) y para algunas versiones de SQL particularizadas por los fabricantes de algunos de los sistemas de bases de datos más evolucionados.
El Modelo Relacional
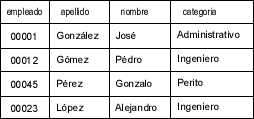
Aunque SQL está basado en el modelo relacional, no representa una implementación excesivamente rígida. En él, las unidades básicas son tablas, columnas y filas. Si se habla estrictamente en términos relacionales, la relación es mapeada en una tabla y proporciona una forma de relacionar los datos dentro de una tabla de forma simple. Una columna representa un dato presente en la tabla, mientras que una fila representa un registro, o entrada, de la tabla. Cada fila contiene un valor determinado para cada una de las columnas (un valor puede estar vacío, o indefinido, y ser considerado válido). La tabla se puede visualizar como una matriz, con las columnas en vertical y las filas en horizontal. La tabla siguiente Empleados, por ejemplo, se podría utilizar para almacenar los empleados de una empresa.
Unas cuantas reglas sintácticas básicas de SQL, sobre las que el lector debe prestar especial atención, o tener cuidado, son:
- SQL no es sensible a los espacios en blanco. Los retornos de carro, tabuladores y espacios en blanco no tienen ningún significado especial a la hora de la ejecución de sentencias. Las palabras clave y comandos están delimitados por comas (,), cuando es necesario, y se utilizan paréntesis para agruparlos.
- Cuando se realizan múltiples consultas a un mismo tiempo, se debe utilizar el punto y coma (;) para separar cada una de las consultas.
- Las consultas no son sensibles a mayúsculas o minúsculas. Sin embargo, hay que prestar mucha atención, porque aunque en las palabras clave no importe el que estén en mayúsculas o minúsculas, en las cadenas que se almacenen en las tablas como valores sí que permanece el que se hayan introducido en mayúsculas o minúsculas; y hay que tener esto presente, sobre todo a la hora de hacer comparaciones.
Aunque se pueden tener todos los datos en una sola tabla, no es habitual que esto sirva para todos los casos. Por ejemplo, si en la tabla anterior de Empleados, se quisiera ahora añadir información sobre los departamentos de la empresa y en cuáles están adscritos los empleados, se podría añadir a esa misma tabla; sin embargo, el propósito de la tabla Empleados es almacenar datos sobre los empleados, no sobre la empresa. La solución consiste en crear otra tabla, Departamentos, en donde guardar la información específica de los departamentos de la empresa. Para asociar un empleado con un departamento, solamente habría que añadir una columna a la tabla Empleados para guardar el nombre o número del departamento. Ahora que ya están colocados los empleados en cada departamento, se puede incorporar otra tabla para guardar información de los Proyectos en que están involucrados.
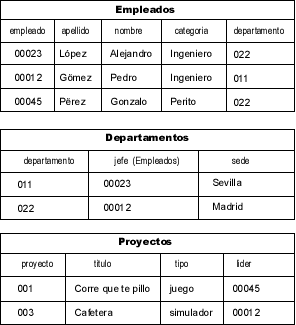
Ahora está más claro cómo están separados lógicamente los datos. Este proceso es el que más tiempo requiere en el desarrollo de una base de datos, y representa el primer nivel en donde se declara el esquema de las relaciones. El esquema de la bases de datos es el contenedor de más alto nivel que la define como una colección de tablas, en donde cada tabla cae dentro de un esquema. Del mismo modo, un catálogo es una entidad que puede englobar a varios esquemas. Esta abstracción es precisamente la parte más necesaria dentro de un robusto sistema relacional de bases de datos (RDBMs).
La razón principal de una base de datos es el acceso a la información, es decir, facilitar que se pueda leer una tabla, que se pueda cambiar la información que contiene, y también que se puedan crear y destruir tablas. Además, permite que se establezcan niveles de seguridad, pro ejemplo, se puede incorporar otra tabla, llamada Condifencial, para guardar la dirección, teléfono y sueldo de cada empleado, que tendrá que estar colocada en un esquema separado para que solamente el departamento de tesorería pueda acceder a esos datos.
Si se observan las tablas anteriores, las tres se encuentran enlazadas. La tabla Empleados contiene una columna que contiene el número del departamento al que pertenece cada empleado. Este número de departamento también aparece en la tabla Departamentos, que describe cada departamento de la empresa. Las tablas Empleados y la nueva Confidencial, están relacionadas, pero todavía se necesita incorporar una entrada en una de las tablas que permita acceder a la otra, para hacer una distinción con el número de empleado.
El enlace que se ha establecido, entre número de empleado y número de departamento, se conoce como índice (key). Un índice se utiliza para identificar información dentro de una tabla. Cada empleado individual o departamento, deberían tener un único índice para facilitar posteriores acciones sobre las tablas. Según el modelo relacional, el índice se supone único dentro de una tabla, ninguna otra entrada en la tabla debe tener el mismo índice primario, o clave primaria.
Una sola columna suele ser suficiente para identificar inequívocamente a una fila o entrada. Sin embargo, también se puede usar una combinación de filas para componer un índice primario. Por ejemplo, se puede utilizar una combinación del departamento y sede de ese departamento para componen su clave primaria. En SQL, las columnas definidas como claves primarias, deben estar definidas, no pueden ser nulas.
Lo mejor es, pues, repartir los datos en tablas donde se encuentren lógicamente asociados; aunque, puede ser que haya datos que deban estar en más de una tabla, como es en este caso el número de empleado, que debe estar en la tabla Empleados y en la tabla Confidencial. Se puede necesitar tener la seguridad de que si una fila existe en una tabla, es necesario que exista la correspondiente fila en la tabla relacionada; en el ejemplo, se puede decir que por cada entrada en la tabla de Empleados debe haber otra entrada en la tabla Confidencial. Esta asociación se puede solidificar con el uso de claves ajenas, donde una columna determinada en una tabla depende de otra columna en la tabla padre. En esencia, se está construyendo una columna virtual en una tabla, en base a una columna real de otra tabla. En el ejemplo, se ha enlazado la columna con el número del empleado de la tabla Confidencial al número de empleado de la tabla Empleados; se está indicando que el número de empleado es un índice en la tabla Confidencial, de ahí el término de clave ajena. Una clave primaria también puede contener una clave ajena si es necesario.
La forma en que se modelan los datos y las técnicas que se utilizan para construir claves primarias y ajenas, caen dentro del diseño de bases de datos, que esta pequeña introducción a SQL no puede abordar.
Creación de Tablas
La sentencia CREATE TABLE es la que se usa para crear una tabla. Es una operación importante pero muy sencilla. Hay algunas fuentes de datos que solamente admiten en las tablas elementos muy simples, como por ejemplo, las fuente de texto accedidas a través de ODBC. El formato de la sentencia es:
CREATE TABLE <nombre tabla> (<elemento columna> [,<elemento columna]...)
El elemento columna se declara de la forma:
<nombre columna> <tipo de dato> [DEFAULT <expresión>]
[<constante columna> [,<constante columna]...]
Siendo constante columna quien indica la forma o característica de la columna, que puede ser:
NOT NULL | UNIQUE | PRIMARY KEY
Siguiendo con el ejemplo, en este caso lo único que hay que tener presente es que es necesario definir la tabla de referencia, en este caso Empleados, antes de definir la tabla que hace referencia a ella, en este caso Confidencial. La tabla Empleados se crearía de la siguiente forma:
CREATE TABLE Empleados (
empleado CHAR(5) PRIMARY KEY,
apellido VARCHAR(20) NOT NULL,
nombre VARCHAR(20) NOT NULL,
categoria VARCHAR(20) NOT NULL,
departmento VARCHAR(20) );
En la creación de la tabla se utilizan dos tipos de datos para especificar cadenas: CHAR y VARCHAR. El sistema de base de datos utiliza exactamente la cantidad de espacio que se indique cuando se utiliza un tipo de datos CHAR; en caso de que se indique que una entrada es de tipo CHAR(n) y se rellene con una cena de tamaño inferior a n , los caracteres que resten se rellenan con espacios. Con VARCHAR, se almacena exactamente la cadena que se indique, el tamaño que se indica en la creación solamente sirve para fijar el tamaño máximo del valor que se puede almacenar.
También se utiliza la directiva NOT NULL que hace que se compruebe cada una de las entradas en la columna. La creación de la tabla Confidencial es igualmente sencilla, la única diferencia es la incorporación de la palabra clave REFERENCES para que esta tabla pueda utilizar el atributo correspondiente al número de empleado de la tabla Empleados como su clave primaria.
CREATE TABLE Confidencial (
empleado CHAR(5) PRIMARY KEY,
direccion VARCHAR(50),
telefono VARCHAR(12),
sueldo DECIMAL,
FOREIGN KEY( empleado ) REFERENCES Empleados( empleado ) );
La sentencia para eliminar una tabla es DROP TABLE, que es igual de sencilla que la sentencia de creación, y su forma es:
DROP TABLE <nombre tabla>
Recuperar Información
La sentencia SELECT es la que se utiliza cuando se quieren recuperar datos de la información almacenada en un conjunto de columnas. Las columnas pueden pertenecer a una o varias tablas y se puede indicar el criterio que deben seguir las filas de información que se extraigan. Muchas de las cláusulas que permite esta sentencia son simples, aunque se pueden conseguir capacidades muy complejas a base de una gramática más complicada.
Desde luego, la mejor forma de entender el proceso de consulta a la base de datos y el uso de las cláusulas que modifican al comando SELECT, es pensar en términos de conjuntos matemáticos. SQL, al igual que todos los lenguajes de cuarta generación está diseñado para responder a cuestiones de tipo żQué quiero hacer?, al contrario que los otros lenguajes de programación, como Java y C++, que intentan resolver cuestiones del tipo żCómo lo hago?.
El dominio de las consultas SQL no es una tarea sencilla, pero con un poco de sentido común y algo de intuición se pueden conseguir resultados muy eficientes, gracias al modelo relacional en el que se base SQL.
La sintaxis de la sentencia es:
SELECT [ALL | DISTINCT] <seleccion>
FROM <tablas>
WHERE <condiciones de seleccion>
[ORDER BY <columna> [ASC | DESC]
[,<columna> [ASC | DESC]]...]
La seleccion contiene normalmente una lista de columnas separadas por coma (,), o un asterisco (*) para seleccionarlas todas. Un ejemplo ejecutado contra una de las tablas creadas anteriormente podría ser:
SELECT * FROM Empleados;
Que devolvería el contenido completo de la tabla. Si solamente se quieren conocer los empleados del departamento 022, la consulta sería:
SELECT * FROM Empleados
WHERE departamento = '022';
Para ordenar la lista resultante por apellidos, por ejemplo, se usaría la directiva ORDER BY:
SELECT * FROM Empleados
WHERE departamento = '022'
ORDER BY apellido;
Si lo que se quiere, además de que la lista esté ordenada por apellido, es ver solamente el número de empleado, se consultaría de la forma:
SELECT empleado FROM Empleados
WHERE departamento = '022'
ORDER BY apellido;
Si se quieren resultados de dos tablas a la vez, tampoco hay problema en ello, tal como se muestra en la siguiente sentencia:
SELECT Empleados.*, Confidencial.*
FROM Empleados, Confidencial;
También se pueden realizar consultas más complicadas; por ejemplo, mostrar el sueldo de los empleados del departamento 022. Según las tablas, la información del sueldo se encuentra en la tabla Confidencial, y el departamento al que está adscrito un empleado se encuentra en la tabla Empleados. Para asociar una comparación de una tabla con otra, se puede utilizar las referencia la número de empleado en la tabla Confidencial desde la tabla Empleados. Se pueden especificar los empleados que pertenecen a un departamento y utilizar los números de empleados resultantes para obtener la información sobre su sueldo desde la tabla Confidencial.
SELECT c.sueldo
FROM Empleados AS e, Confidencial AS c
WHERE e.departmento = '022'
AND c.empleado = e.empleado;
Aquí se ha declarado algo parecido a una variable con la cláusula AS. Ahora se pueden hacer referencias a campos específicos de la tabla utilizando un punto (.), como si se tratase de un objeto. Se puede, por ejemplo, determinar cuántos empleados de la empresa tienen un sueldo por encima de los 1200 euros.
SELECT salary
FROM Confidencial
WHERE sueldo > 1200;
Y también se pueden conocer los empleados del departamento 022 que cobran más de los 1200 euros.
SELECT c.sueldo
FROM Empleados AS e, Confidencial AS c
WHERE e.departmento = '022'
AND c.empleado = e.empleado
AND c.sueldo > 1200;
También se pueden realizar un cierto número de funciones en SQL, incluyendo algunos cálculos matemáticos y estadísticos. Por ejemplo, se puede saber la media de sueldo de los empleados del departamento 022 de la siguiente forma:
SELECT AVG( c.sueldo )
FROM Empleados as e, Confidencial as c
WHERE e.departmento = '022'
AND c.empleado = e.empleado;
Desde luego, las posibilidades que ofrece SQL exceden en mucho el alcance de este capítulo y los pocos ejemplos que se han presentado. Además, como el interés del autor es introducir a JDBC, tampoco es necesario el uso de ejemplos complejos. Si el lector tiene interés en aprender más sobre SQL, debería recurrir a uno de los muchos y buenos libros que hay publicados sobre ello.
Almacenar Información
La sentencia INSERT se utiliza cuando se quieren insertar filas de información en las columnas. Aquí también se pueden presentar diferentes capacidades, dependiendo del nivel de complejidad soportado. La sintaxis de la sentencia es:
INSERT INTO <nombre tabla>
[(<nombre columna> [,<nombre columna]...)]
VALUES (<expresion> [,<expresion>]...)
Por ejemplo, en la tabla de los Empleados se podría ingresar uno nuevo con la siguiente información:
INSERT INTO Empleados
VALUES ( ’00066’, ’Garrido’, ’Juan’, ’Ingeniero’ , ’022’ );
Si la gramática del driver utilizado lo soporta, se puede utilizar una cláusula SELECT para cargar varias columnas a la vez.
La sentencia DELETE es la que se emplea cuando se quieren eliminar filas de las columnas, y su gramática también es muy simple:
DELETE FROM <nombre tabla> WHERE <condicion busqueda>
Si no se especifica la cláusula WHERE, se eliminará el contenido de la tabla completamente, sin eliminar la tabla, por ejemplo:
DELETE FROM Empleados;
Vaciará completamente la tabla, dejándola sin ningún dato en las columnas, es decir, esencialmente lo que hace es borrar todas las columnas de la tabla. Especificando la cláusula WHERE, se puede introducir un criterio de selección para el borrado, por ejemplo:
DELETE FROM Empleados WHERE empleado=’00001’;
También se pueden borrar múltiples filas en esta operación, siempre que la cláusula WHERE permita seleccionar más de una fila, todas ellas serán eliminadas.
Para actualizar filas ya existentes en las columnas, se utiliza la sentencia UPDATE, cuya gramática es mínima:
UPDATE <nombre tabla>
SET <nombre columna = ( <expresion> | NULL )
[, <nombre columna = ( <expresion> | NULL )]...
WHERE <condicion busqueda>
Este comando permite cambiar uno o más campos existentes en una fila. Por ejemplo, para cambiar el nombre de un empleado en la tabla de Empleados, se haría:
UPDATE Empleados
SET nombre = 'Pedro Juan'
WHERE empleado='00012';
Código Independiente y Portable
De nuevo, tenga el lector presente que lo que a continuación se refleja son simples opiniones y sugerencias, que solamente están destinadas a que los problemas que se presenten sean los menos posibles, cuando se intente programar con Java, y en este caso, con JDBC.
Uno de los objetivos fundamentales a la hora de diseñar JDBC fue obtener la máxima portabilidad posible entre distintos Sistemas de Gestión de Bases de Datos. Distintos gestores tienden a utilizar distinta sintaxis para las mismas cosas, como por ejemplo para especificar una fecha, ejecutar un procedimiento almacenado, etc. JDBC proporciona una serie de cláusulas de escape de modo que se pueda escribir una fecha, etc., de forma portable: será luego el driver el que se encargue de convertir la información al formato que requiere la base de datos. Todas las cláusulas de escape se escriben siempre entre llaves, "{...}".
Una fecha se especifica utilizando el formato {d 'aaaa-mm-dd'}, donde d indica que se está hablando de una fecha, y aaaa serán los cuatro dígitos correspondientes a un año, mm los dos dígitos del mes, y dd los dos dígitos del día. Una hora se escribirá utilizando el formato {t 'hh:mm:ss'}, donde se usa hh para la hora, mm para los minutos, y ss para los segundos. Para un valor de fecha/hora se utilizará {ts 'aaaa-mm-dd hh:mm:ss.f . . .'}, donde f, la parte fraccionaria de los segundos, es optativo.
No sólo se utilizan cláusulas de escape para las constantes de fecha y hora, también para llamar a un procedimiento almacenado hay una sintaxis especial que permite aislarse de la sintaxis concreta de cada base de datos: el formato será {call nombre_proc[(?, ?, . . .)]}, donde call indica que se está invocando un procedimiento almacenado, nombre_proc será su nombre, y los distintos parámetros, si los hay, se indicarán mediante una serie de caracteres de interrogación, ?, encerrados entre paréntesis.
También para invocar una función SQL existe una cláusula de escape, con la sintaxis {fn upper( "Texto")}, donde fn indica que estamos llamando a una función, de nombre upper, y a la que se le pasa el argumento "Texto".
También hay cláusulas de escape para las composiciones externas (outer-joins), utilizando la sintaxis {oj outer-join}, donde outer-join tiene la forma :
tabla LEFT OUTER JOIN {tabla | outer-join} ON condición_de_búsqueda
A la hora de utilizar dentro de un SELECT la palabra reservada LIKE se pueden usar dos caracteres como comodín, (_) y (%). Para buscar en la base de datos un texto en que aparezcan estos dos caracteres, basta con poner delante de ellos un carácter especial que indique que en ese lugar se utilizan como cualquier otro carácter, no como comodines. Para ello, se debe indicar cuál es dicho carácter especial utilizando la sintaxis {escape 'carácter'}, por ejemplo
SELECT nombre FROM Empleados WHERE nombre LIKE '@_' {escape '@'}
En este ejemplo, se indica que el carácter especial de escape es @, por lo que la cadena LIKE '@_' indica que se deben buscar todos los nombre que comiencen por '_', en lugar de usarlo como comodín.
Si se quiere escribir código JDBC para que sea portable e independiente de la máquina y motor de base de datos que se va a atacar, deberían, además de tener en cuenta las recomendaciones anteriores, seguirse unas sencillas reglas a la hora de escribir código. Algunas de ellas son las que se recogen en los siguientes párrafos.
- Presérvese siempre el uso de mayúsculas y minúsculas de la salida de los métodos getTables() y getColumns()
- Llamar al método getIdentifierQuoteString() y utilizar la cadena que devuelva para delimitar los identificadores
- Tener en cuenta que no todos los sistemas soportan SQL ’92 estrictamente
- Utilícese setNull()
PreparedStatement stmt = con.prepareStatement(
"update nombre set departamento = ? where empleado = 00012" );
stmt.setString( 1,"" ); // Erróneo!!
stmt.setNull( 1 );
stmt.executeUpdate();
- Comprobar los límites de la sesión con getMaxStatements() y getMaxConnections(). Por ejemplo, Microsoft SQL restringe a una sola sentencia activa y hay algunos drivers que limitan las conexiones a una sola
- Utilizar las comillas ...pero no en todas partes
- Las pseudo-columnas nunca deben ir entre comillas. Por ejemplo, filaid, regid, usuario, empleado
- Tener cuidado con algunas cosas de SQL ’92:
"select * from Empleados where empleado = NULL"
// nunca devuelve filas!
"select * from Empleados where empleado is NULL"
// puede devolver filas
"select * from Empleados where empleado = ?"
// usar setNull para el parámetro
// nunca devolverá filas
- Tener cuidado con los Nombres, si supportSchemasInDataManipulation() indica que sí se pueden soportar esquemas, utilizar siempre un punto (.) entre el nombre del esquema y el nombre de la tabla. ˇNo olvidar las comillas!
- A la hora de crear una tabla usar getTypeInfo() y buscar entre el resultado las mejores opciones. Por ejemplo, si se quiere crear una columna DECIMAL(8,0), buscar un SQL DECIMAL o SQL NUMERIC, luego SQL INTEGER, luego SQL DOUBLE o SQL FLOAT, luego SQL CHAR o SQL VARCHAR; e ignorar tipos que no coincidan con los requerimientos: moneda, autoincremento, etc.
- Utilizar parámetros en lugar de constantes en las sentencias SQL
- Algunas bases de datos no soportan constantes cadena para columnas LONG
- Usar setObject(), que reduce la complejidad del programa. Por ejemplo, si se usan buffers de cadenas, entonces es necesario setObject()
- Para parámetros de salida, no olvidarse de utilizar registerOutParameter()
| 