Bases de Datos
|
|
|
|
Bases de Datos |
| Anterior | Siguiente |
|
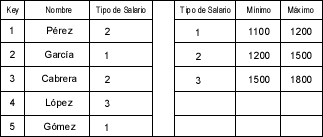
Una Base de Datos es una serie de tablas que contienen información ordenada en alguna estructura que facilita el acceso a esas tablas, ordenarlas y seleccionar filas de las tablas según criterios específicos. Las bases de datos generalmente tienen índices asociados a alguna de sus columnas, de forma que el acceso sea lo más rápido posible. Las Bases de Datos son, sin lugar a dudas, las estructuras más utilizadas en ordenadores; ya que son el corazón de sistemas tan complejos como el censo de una nación, la nómina de empleados de una empresa, el sistema de facturación de una multinacional, o el medio por el que nos expiden el billete para las próximas vacaciones. En el caso, por ejemplo, del registro de trabajadores de una empresa, se puede imaginar una tabla con los nombres de los empleados y direcciones, y sueldos, retenciones y beneficios. Para organizar esta información, se puede empezar con una tabla que contenga los nombres de los empleados, su dirección y su número de teléfono. También se podría incluir la información relativa a su sueldo, categoría, última subida de salario, etc. ┐Podría todo esto colocarse en una sola tabla? Casi seguro que no. Los rangos de salario para diferentes empleados probablemente sean iguales, por lo que se podría optimizar la tabla almacenando solamente el tipo de salario en la tabla de empleados y los rangos de salario (en euros) en otra tabla, indexada a través del tipo de salario. Por ejemplo
Los datos de la columna Tipo de Salario están referidos a la segunda tabla. Se pueden imaginar muchas categorías para estas tablas secundarias, como por ejemplo la provincia de residencia y los tipos de retención de Hacienda, o si tiene seguro de vida, vivienda propia, coche, apartamento en la playa, casa en el campo, etc. Cada tabla tiene una primera columna que sirve de clave para las demás columnas, que ya contienen datos. La construcción de tablas en las bases de datos es tanto un arte como una ciencia, y su estructura está referida por su forma normal. Las tablas se dice que están en primera, segunda o tercera forma normal, o de modo abreviado como 1NF, 2NF o 3NF.
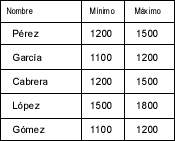
Actualmente todas las bases de datos se construyen de forma que todas sus tablas están en la Tercera Forma Normal (3NF); es decir, que las bases de datos están constituidas por un número bastante alto de tablas, cada una de ellas con relativamente pocas columnas de información. A la hora de extraer datos de las tablas, se realizan consultas contra ella. Por ejemplo, si se quiere generar una tabla de empleados y sus rangos de salario para algún tipo de plan especial de la empresa, esa tabla no existe directamente en la base de datos, así que debe construirse haciendo una consulta a la base de datos, y se obtendría una tabla que contendría la siguiente información:
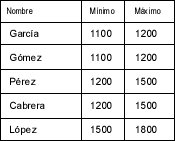
O quizá ordenada por el incremento de salario:
Para generar la tabla anterior se habría de realizar una consulta a la base de datos que tendría la siguiente forma: SELECT DISTINCTROW Empleados.Nombre, TipoDeSalario.Minimo,
TipoDeSalario.Maximo FROM Empleados INNER JOIN TipoDeSalario ON
Empleados.SalarioKey = TipoDeSalario.SalarioKey
ORDER BY TipoDeSalario.Minimo;
El lenguaje en que se ha escrito la consulta es SQL, actualmente soportado por casi todas las bases de datos a lo largo del mundo. Los estándares de SQL han sido varios a lo largo de los años y muchas de las bases de datos para PC soportan alguno de esos tipos. El estándar SQL-92 es el que se considera origen de todas las actualizaciones. Hay que tener en cuenta, que hay posteriores versiones de SQL, perfeccionadas y extendidas para explotar características únicas de bases de datos particulares; así que no conviene separarse del estándar básico si se pretende hacer una aplicación que pueda atacar a cualquier tipo de base de datos. Al final del capítulo, el lector puede encontrar una pequeña revisión del lenguaje SQL. Desde que los PC se han convertido en una herramienta presente en la mayor parte de las oficinas, se han desarrollado un gran número de bases de datos para ejecutarse en ese tipo de plataformas; desde bases de datos muy elementales como Microsoft Works, hasta otras ya bastante sofisticadas como Approach, dBase, Paradox, Access y Foxbase. Otra categoría ya mßs seria de bases de datos para PC son aquellas que usan la plataforma PC como cliente para acceder a un servidor. Estas bases de datos son IBM DB/2, Microsoft SQL Server, Oracle, Sybase, SQLBase, Informix, XDB y Postgres. Todas estas bases de datos soportan varios dialectos similares de SQL, y todas parecen, a primera vista, intercambiables. La razón de que no sean intercambiables, por supuesto, es que cada una está diseñada con unas características de rendimiento distintas, con un interfaz de usuario y programación diferente. Aunque todas ellas soportan SQL y la programación es similar, cada base de datos tiene su propia forma de recibir las consultas SQL y su propio modo de devolver los resultados. Aquí es donde aparece el siguiente nivel de estandarización, de la mano de ODBC (Open DataBase Conectivity). La idea es que se pueda escribir código independientemente de quien sea el propietario de la base de datos a la que se quiera acceder, de forma que se puedan extraer resultados similares de diferentes tipos de bases de datos sin necesidad de tocar el código del programa. Si se consiguiese escribir alguna forma de trazadores para estas bases de datos que tuviesen un interfaz similar, el objetivo no sería difícil de alcanzar. Microsoft hizo su primer intento en 1992, con la especificación que llamaron Object Database Connectivity; y que se suponía iba a ser la respuesta a la conexión a cualquier tipo de base de datos desde Windows. Como en toda aplicación informática, esta no fue la única versión, sino que hubo varias hasta llegar a la de 1994, que era más rápida y más estable, además de ser la primera de las versiones de 32 bits. Y, por si fuera poco, ODBC comenzó a desplazarse a otras plataformas diferentes de Windows, acaparando además de los PC también el mundo de las estaciones de trabajo. Tanto es así, que ahora casi todos los fabricantes de bases de datos proporcionan un driver ODBC para acceder a su base de datos. Sin embargo, ODBC dista mucho de ser la panacea que en un principio se podía pensar y que Microsoft se encargó de hacer creer. Muchos fabricantes de bases de datos soportan ODBC como un interfaz alternativo al suyo estándar, y la programación en ODBC no es nada, pero que nada trivial; incluyendo toda la parafernalia de la programación para Windows con handles, punteros y opciones que son duras de asimilar. Finalmente, ODBC no es un estándar libre, ha sido desarrollado y es propiedad de Microsoft, lo cual, dados los vientos que soplan en este competitivo mundo de las compañías de software, hace su futuro difícil de predecir. |
|