This is a simple example of Bayesian inference using the Metropolis algorithm.
We start from a sample of size 10 taken from a normal density with $\mu=1$ and $\sigma = 1/2$. The sample mean is 1.09 and the sample std is 0.55.
First we estimate the posterior distribution of the mean when σ is known (and uniform prior):
(Acceptance ratio: 0.1896 )
The mean and std of the posterior mean is consistent with what we expect: 1.09, 0.16 , and $\sigma/\sqrt n = 0.16$.
We also show a 96% credible interval in the histograms.
Now we compute the posterior σ for known μ, in this case using the noninformative prior $\sigma^{ -1 }$:
(Acceptance ratio: 0.156 )
If nothing is known about the parameters we get slightly heavier tails:
(Acceptance ratio: 0.1327 , with $\sigma_m = 0.3$).
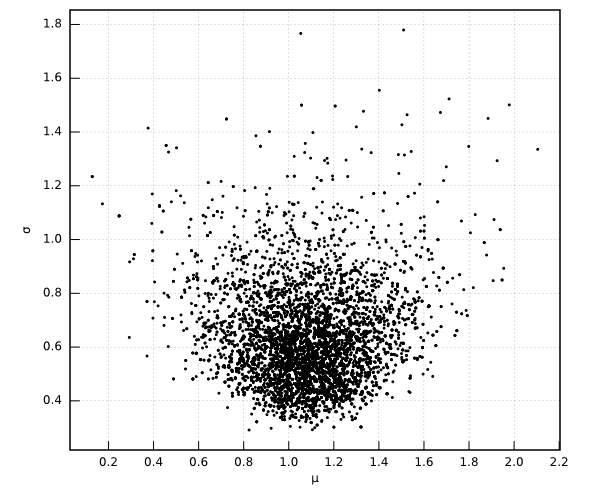
This is the joint distribution of $(\mu,\sigma)$:
We add a few outliers:
If we use a simple Gaussian model the estimated posterior distributions obviously have large dispersion:
(Acceptance ratio: 0.3877 , with $\sigma_m = 0.5$).
A better model for this kind of data is a mixture of normal ($\mu$,$\sigma$) with weight $(1-p)$ and a much wider normal (0,5) with weight $p$. We set a uniform prior on $p$.
The result is quite good: the posterior $\mu$ and $\sigma$ are similar to the case with clean data:
The posterior distribution of the ratio of outliers shows that this ratio is around 0.3, although a precise value cannot be determined from this sample size.
(Acceptance ratio: 0.2034 , with $\sigma_m = 0.02$).
If we use this robust model with the initial "clean" data we get the following result:
From a naive machine learning viewpoint it is quite remarkable that the intervals estimated by this richer model are only slightly wider than those obtained by the simpler normal model.
The posterior distribution of the ratio of outliers that we get in this case (which can be considered as a nuisance parameter) shows that the outliers are unlikely now, but again they cannot be ruled out from this small sample.
The shape of this distribution is qualitatively different now. As the sample size increases, the probability mass of the ratio of outliers moves to the left (towards $p=0$), but since samples from the outlier distribution can also appear in the region of the clean data we will always obtain a small tail over $p>0$.
In any case, the marginal distributions for $\mu$ and $\sigma$ provide excellent estimations without any overfitting.
(Acceptance ratio: 0.1735 , with $\sigma_m = 0.05$).
(in construction)
The power of the Bayesian approach, working from such basic principles, is impressive. In combination with Metropolis and other sampling algorithms we can solve interesting and nontrivial problems using a few lines of code.